Random value X has a normal distribution (or Gaussian distribution) if its probability density has the form:
,
where are the parameters A– any real number and σ >0.
The graph of the differential normal distribution function is called a normal curve (Gaussian curve). The normal curve (Fig. 2.12) is symmetrical about the straight line X =A, has a maximum ordinate, and at points X = A± σ – inflection.
Rice. 2.12
It has been proven that the parameter A is the mathematical expectation (also mode and median), and σ is the standard deviation. The coefficients of skewness and kurtosis for a normal distribution are equal to zero: As = Ex = 0.
Let us now establish how changing the parameters affects A and σ looks like a normal curve. When changing a parameter A the shape of the normal curve does not change. In this case, if the mathematical expectation (parameter A) decreased or increased, the graph of the normal curve shifts to the left or right (Fig. 2.13).
When the parameter σ changes, the shape of the normal curve changes. If this parameter increases, then the maximum value of the function decreases, and vice versa. Since the area limited by the distribution curve and the axis Oh, must be constant and equal to 1, then with increasing parameter σ the curve approaches the axis Oh and stretches along it, and with a decrease in σ the curve contracts to a straight line X = A(Fig. 2.14).
Rice. 2.13 Fig. 2.14
Normal distribution density function φ( X) with parameters A= 0, σ = 1 is called density of the standard normal random variable
, and its graph is a standard Gaussian curve.
The density function of a normal standard value is determined by the formula, and its graph is shown in Fig. 2.15.
From the properties of mathematical expectation and dispersion it follows that for the quantity , D(U)=1, M(U) = 0. Therefore, the standard normal curve can be considered as the distribution curve of the random variable , where X– a random variable subject to the normal distribution law with parameters A and σ.
The normal distribution law of a random variable in integral form has the form
(2.10)
Putting in the integral (3.10) we obtain
,
Where . The first term is equal to 1/2 (half the area of the curved trapezoid shown in Fig. 3.15). Second term
(2.11)
called Laplace function
, as well as the probability integral.
Since the integral in formula (2.11) is not expressed in terms of elementary functions, for convenience of calculations it is compiled for z≥ 0 Laplace function table. To calculate the Laplace function for negative values z, it is necessary to take advantage of the oddness of the Laplace function: Ф(– z) = – Ф( z). We finally get the calculation formula
From this we obtain that for a random variable X, obeying the normal law, the probability of its falling on the segment [α, β] is
(2.12)
Using formula (2.12), we find the probability that the modulus of deviation of the normal distribution of the quantity X from its distribution center A less than 3σ. We have
P(| x – a| < 3 s) =P(A–3 s< X< A+3 s)= Ф(3) – Ф(–3) = 2Ф(3) »0.9973.
The value of Ф(3) was obtained from the Laplace function table.
It is generally accepted that the event practically reliable
, if its probability is close to one, and practically impossible if its probability is close to zero.
We got the so-called three sigma rule
: for normal distribution event (| x–a| < 3σ) практически достоверно.
The three-sigma rule can be formulated differently: although the normal random variable is distributed along the entire axis X, the range of its practically possible values is(a–3σ, a+3σ).
The normal distribution has a number of properties that make it one of the most commonly used distributions in statistics.
If it is possible to consider a certain random variable as the sum of a sufficiently large number of other random variables, then this random variable usually obeys the normal distribution law. The summable random variables can obey any distributions, but the condition of their independence (or weak independence) must be met. Also, none of the summed random variables should differ sharply from the others, i.e. each of them should play approximately the same role in the total and not have an exceptionally large dispersion compared to other quantities.
This explains the wide prevalence of the normal distribution. It occurs in all phenomena and processes where the scattering of a random variable under study is caused by a large number of random causes, the influence of each of which individually on the scattering is negligible.
Most of the random variables encountered in practice (such as, for example, the number of sales of a certain product, measurement error; deviation of projectiles from the target in range or direction; deviation of the actual dimensions of parts processed on a machine from the nominal dimensions, etc.) can be is presented as the sum of a large number of independent random variables that have a uniformly small effect on the dispersion of the sum. Such random variables are considered to be normally distributed. The hypothesis about the normality of such quantities finds its theoretical justification in the central limit theorem and has received numerous practical confirmations.
Let's imagine that a certain product is sold in several retail outlets. Due to the random influence of various factors, the number of sales of goods at each location will vary slightly, but the average of all values will approach the true average number of sales.
Deviations of the number of sales at each outlet from the average form a symmetrical distribution curve, close to the normal distribution curve. Any systematic influence of any factor will manifest itself in the asymmetry of the distribution.
Task. The random variable is normally distributed with parameters A= 8, σ = 3. Find the probability that the random variable as a result of the experiment will take a value contained in the interval (12.5; 14).
Solution. Let's use formula (2.12). We have
Task. Number of items sold per week of a certain type X can be considered normally distributed. Mathematical expectation of the number of sales
thousand pieces The standard deviation of this random variable is σ = 0.8 thousand pcs. Find the probability that from 15 to 17 thousand units will be sold in a week. goods.
Solution. Random value X distributed normally with parameters A= M( X) = 15.7; σ = 0.8. You need to calculate the probability of inequality 15 ≤ X≤ 17. Using formula (2.12) we obtain
The distribution function in this case, according to (5.7), will take the form:
where: m – mathematical expectation, s – standard deviation.
The normal distribution is also called Gaussian after the German mathematician Gauss. The fact that a random variable has a normal distribution with parameters: m, is denoted as follows: N (m,s), where: m =a =M ;
Quite often in formulas, the mathematical expectation is denoted by A . If a random variable is distributed according to the law N(0,1), then it is called a normalized or standardized normal variable. The distribution function for it has the form:
|
|
 .
.The density graph of a normal distribution, which is called a normal curve or Gaussian curve, is shown in Fig. 5.4.

Rice. 5.4. Normal distribution density
The determination of the numerical characteristics of a random variable by its density is considered using an example.
Example 6.
A continuous random variable is specified by the distribution density: ![]() .
.
Determine the type of distribution, find the mathematical expectation M(X) and variance D(X).
Comparing the given distribution density with (5.16), we can conclude that the normal distribution law with m = 4 is given. Therefore, mathematical expectation M(X)=4, variance D(X)=9.
Standard deviation s=3.
The Laplace function, which has the form:
|
|
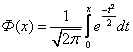 ,
,is related to the normal distribution function (5.17), the relation:
F 0 (x) = Ф(x) + 0.5.
The Laplace function is odd.
Ф(-x)=-Ф(x).
The values of the Laplace function Ф(х) are tabulated and taken from the table according to the value of x (see Appendix 1).
The normal distribution of a continuous random variable plays an important role in probability theory and in describing reality; it is very widespread in random natural phenomena. In practice, very often we encounter random variables that are formed precisely as a result of the summation of many random terms. In particular, an analysis of measurement errors shows that they are the sum of various types of errors. Practice shows that the probability distribution of measurement errors is close to the normal law.
Using the Laplace function, you can solve the problem of calculating the probability of falling into a given interval and a given deviation of a normal random variable.
In many problems related to normally distributed random variables, it is necessary to determine the probability of a random variable , subject to a normal law with parameters, falling on the segment from to . To calculate this probability we use the general formula
where is the distribution function of the quantity .
Let's find the distribution function of a random variable distributed according to a normal law with parameters. The distribution density of the value is equal to:
 .
(6.3.2)
.
(6.3.2)
From here we find the distribution function
 . (6.3.3)
. (6.3.3)
Let us make a change of variable in the integral (6.3.3)
and let's put it in this form:
 (6.3.4)
(6.3.4)
The integral (6.3.4) is not expressed through elementary functions, but it can be calculated through a special function expressing a certain integral of the expression or (the so-called probability integral), for which tables have been compiled. There are many varieties of such functions, for example:
 ;
;

etc. Which of these functions to use is a matter of taste. We will choose as such a function
 . (6.3.5)
. (6.3.5)
It is easy to see that this function is nothing more than a distribution function for a normally distributed random variable with parameters .
Let us agree to call the function a normal distribution function. The appendix (Table 1) contains tables of function values.
Let us express the distribution function (6.3.3) of the quantity with parameters and through the normal distribution function. Obviously,
![]() .
(6.3.6)
.
(6.3.6)
Now let's find the probability of a random variable falling on the section from to . According to formula (6.3.1)
Thus, we expressed the probability of a random variable distributed according to a normal law with any parameters getting into a section through the standard distribution function corresponding to the simplest normal law with parameters 0.1. Note that the arguments of the function in formula (6.3.7) have a very simple meaning: there is the distance from the right end of the section to the center of scattering, expressed in standard deviations; - the same distance for the left end of the section, and this distance is considered positive if the end is located to the right of the center of dispersion, and negative if to the left.
Like any distribution function, the function has the following properties:
3. - non-decreasing function.
In addition, from the symmetry of the normal distribution with parameters relative to the origin, it follows that
Using this property, strictly speaking, it would be possible to limit the function tables to only positive argument values, but in order to avoid an unnecessary operation (subtraction from one), Appendix Table 1 provides values for both positive and negative arguments.

In practice, we often encounter the problem of calculating the probability of a normally distributed random variable falling into an area that is symmetrical with respect to the center of scattering. Let's consider such a section of length (Fig. 6.3.1). Let's calculate the probability of hitting this area using formula (6.3.7):
Taking into account the property (6.3.8) of the function and giving the left side of formula (6.3.9) a more compact form, we obtain a formula for the probability of a random variable distributed according to the normal law falling into an area symmetrical with respect to the center of scattering:
![]() .
(6.3.10)
.
(6.3.10)
Let's solve the following problem. Let us plot successive segments of length from the center of dispersion (Fig. 6.3.2) and calculate the probability of a random variable falling into each of them. Since the normal curve is symmetrical, it is enough to plot such segments only in one direction.

Using formula (6.3.7) we find:
 (6.3.11)
(6.3.11)
As can be seen from these data, the probabilities of hitting each of the following segments (fifth, sixth, etc.) with an accuracy of 0.001 are equal to zero.
Rounding the probabilities of getting into segments to 0.01 (to 1%), we get three numbers that are easy to remember:
0,34; 0,14; 0,02.
The sum of these three values is 0.5. This means that for a normally distributed random variable, all dispersion (with an accuracy of fractions of a percent) fits within the area .
This allows, knowing the standard deviation and mathematical expectation of a random variable, to roughly indicate the range of its practically possible values. This method of estimating the range of possible values of a random variable is known in mathematical statistics as the “three sigma rule.” The rule of three sigma also implies an approximate method for determining the standard deviation of a random variable: take the maximum practically possible deviation from the mean and divide it by three. Of course, this rough technique can only be recommended if there are no other, more accurate methods for determining.
Example 1. A random variable distributed according to a normal law represents an error in measuring a certain distance. When measuring, a systematic error is allowed in the direction of overestimation by 1.2 (m); The standard deviation of the measurement error is 0.8 (m). Find the probability that the deviation of the measured value from the true value will not exceed 1.6 (m) in absolute value.
Solution. The measurement error is a random variable subject to the normal law with parameters and . We need to find the probability of this quantity falling on the section from to . According to formula (6.3.7) we have:
Using the function tables (Appendix, Table 1), we find:
![]() ;
,
;
,
Example 2. Find the same probability as in the previous example, but provided that there is no systematic error.
Solution. Using formula (6.3.10), assuming , we find:
![]() .
.
Example 3. A target that looks like a strip (motorway), the width of which is 20 m, is fired in a direction perpendicular to the highway. Aiming is carried out along the center line of the highway. The standard deviation in the shooting direction is equal to m. There is a systematic error in the shooting direction: the undershoot is 3 m. Find the probability of hitting a highway with one shot.
Normal probability distribution law
Without exaggeration, it can be called a philosophical law. Observing various objects and processes in the world around us, we often come across the fact that something is not enough, and that there is a norm: 
Here is a basic view density functions normal probability distribution, and I welcome you to this interesting lesson.
What examples can you give? There are simply darkness of them. This is, for example, the height, weight of people (and not only), their physical strength, mental abilities, etc. There is a "main mass" (for one reason or another) and there are deviations in both directions.
These are different characteristics of inanimate objects (same size, weight). This is a random duration of processes, for example, the time of a hundred-meter race or the transformation of resin into amber. From physics, I remembered air molecules: some of them are slow, some are fast, but most move at “standard” speeds.
Next, we deviate from the center by one more standard deviation and calculate the height: 
Marking points on the drawing (green color) and we see that this is quite enough.
At the final stage, we carefully draw a graph, and especially carefully reflect it convex/concave! Well, you probably realized a long time ago that the x-axis is horizontal asymptote, and it is absolutely forbidden to “climb” behind it!
When filing a solution electronically, it’s easy to create a graph in Excel, and unexpectedly for myself, I even recorded a short video on this topic. But first, let's talk about how the shape of the normal curve changes depending on the values of and.
When increasing or decreasing "a" (with constant “sigma”) the graph retains its shape and moves right/left respectively. So, for example, when the function takes the form ![]() and our graph “moves” 3 units to the left - exactly to the origin of coordinates:
and our graph “moves” 3 units to the left - exactly to the origin of coordinates: 
A normally distributed quantity with zero mathematical expectation received a completely natural name - centered; its density function  – even, and the graph is symmetrical about the ordinate.
– even, and the graph is symmetrical about the ordinate.
In case of change of "sigma" (with constant “a”), the graph “stays the same” but changes shape. When enlarged, it becomes lower and elongated, like an octopus stretching its tentacles. And, conversely, when decreasing the graph becomes narrower and taller- it turns out to be a “surprised octopus”. Yes, when decrease“sigma” twice: the previous graph narrows and stretches up twice: 
Everything is in full accordance with geometric transformations of graphs.
A normal distribution with a unit sigma value is called normalized, and if it is also centered(our case), then such a distribution is called standard. It has an even simpler density function, which has already been found in Laplace's local theorem: ![]() . The standard distribution has found wide application in practice, and very soon we will finally understand its purpose.
. The standard distribution has found wide application in practice, and very soon we will finally understand its purpose.
Well, now let's watch the movie:
Yes, absolutely right - somehow undeservedly it remained in the shadows probability distribution function. Let's remember her definition:
– the probability that a random variable will take a value LESS than the variable that “runs through” all real values to “plus” infinity.
Inside the integral, a different letter is usually used so that there are no “overlaps” with the notation, because here each value is associated with improper integral  , which is equal to some number from the interval .
, which is equal to some number from the interval .
Almost all values cannot be calculated accurately, but as we have just seen, with modern computing power this is not difficult. So, for the function  standard distribution, the corresponding Excel function generally contains one argument:
standard distribution, the corresponding Excel function generally contains one argument:
=NORMSDIST(z)
One, two - and you're done: 
The drawing clearly shows the implementation of all distribution function properties, and from the technical nuances here you should pay attention to horizontal asymptotes and the inflection point.
Now let's remember one of the key tasks of the topic, namely, find out how to find the probability that a normal random variable will take the value from the interval. Geometrically, this probability is equal to area between the normal curve and the x-axis in the corresponding section: 
but every time I try to get an approximate value  is unreasonable, and therefore it is more rational to use "light" formula:
is unreasonable, and therefore it is more rational to use "light" formula:
.
! Also remembers , What
Here you can use Excel again, but there are a couple of significant “buts”: firstly, it is not always at hand, and secondly, “ready-made” values will most likely raise questions from the teacher. Why?
I have talked about this many times before: at one time (and not very long ago) a regular calculator was a luxury, and the “manual” method of solving the problem in question is still preserved in educational literature. Its essence is to standardize values “alpha” and “beta”, that is, reduce the solution to the standard distribution: ![]()
Note
: the function is easy to obtain from the general case using linear replacements. Then also:
using linear replacements. Then also:
and from the replacement carried out the formula follows: ![]() transition from the values of an arbitrary distribution to the corresponding values of a standard distribution.
transition from the values of an arbitrary distribution to the corresponding values of a standard distribution.
Why is this necessary? The fact is that the values were meticulously calculated by our ancestors and compiled into a special table, which is in many books on terwer. But even more often there is a table of values, which we have already dealt with in Laplace's integral theorem:
If we have at our disposal a table of values of the Laplace function  , then we solve through it:
, then we solve through it:
Fractional values are traditionally rounded to 4 decimal places, as is done in the standard table. And for control there is Point 5 layout.
I remind you that ![]() , and to avoid confusion always control, a table of WHAT function is in front of your eyes.
, and to avoid confusion always control, a table of WHAT function is in front of your eyes.
Answer is required to be given as a percentage, so the calculated probability must be multiplied by 100 and the result provided with a meaningful comment:
– with a flight from 5 to 70 m, approximately 15.87% of shells will fall
We train on our own:
Example 3
The diameter of factory-made bearings is a random variable, normally distributed with a mathematical expectation of 1.5 cm and a standard deviation of 0.04 cm. Find the probability that the size of a randomly selected bearing ranges from 1.4 to 1.6 cm.
In the sample solution and below, I will use the Laplace function as the most common option. By the way, note that according to the wording, the ends of the interval can be included in the consideration here. However, this is not critical.
And already in this example we encountered a special case - when the interval is symmetrical with respect to the mathematical expectation. In such a situation, it can be written in the form and, using the oddity of the Laplace function, simplify the working formula:

The delta parameter is called deviation from the mathematical expectation, and the double inequality can be “packaged” using module:
![]() – the probability that the value of a random variable will deviate from the mathematical expectation by less than .
– the probability that the value of a random variable will deviate from the mathematical expectation by less than .
It’s good that the solution fits in one line :)
– the probability that the diameter of a randomly taken bearing differs from 1.5 cm by no more than 0.1 cm.
The result of this task turned out to be close to unity, but I would like even greater reliability - namely, to find out the boundaries within which the diameter is located almost everyone bearings. Is there any criterion for this? Exists! The question posed is answered by the so-called
three sigma rule
Its essence is that practically reliable
is the fact that a normally distributed random variable will take a value from the interval ![]() .
.
Indeed, the probability of deviation from the expected value is less than:
or 99.73%
In terms of bearings, these are 9973 pieces with a diameter from 1.38 to 1.62 cm and only 27 “substandard” copies.
In practical research, the three sigma rule is usually applied in the opposite direction: if statistically It was found that almost all values random variable under study fall within an interval of 6 standard deviations, then there are compelling reasons to believe that this value is distributed according to a normal law. Verification is carried out using theory statistical hypotheses.
We continue to solve the harsh Soviet problems:
Example 4
The random value of the weighing error is distributed according to the normal law with zero mathematical expectation and a standard deviation of 3 grams. Find the probability that the next weighing will be carried out with an error not exceeding 5 grams in absolute value.
Solution very simple. By condition, we immediately note that at the next weighing (something or someone) we will almost 100% get the result with an accuracy of 9 grams. But the problem involves a narrower deviation and according to the formula ![]() :
:
![]() – the probability that the next weighing will be carried out with an error not exceeding 5 grams.
– the probability that the next weighing will be carried out with an error not exceeding 5 grams.
Answer:
The solved problem is fundamentally different from a seemingly similar one. Example 3 lesson about uniform distribution. There was an error rounding measurement results, here we are talking about the random error of the measurements themselves. Such errors arise due to the technical characteristics of the device itself. (the range of acceptable errors is usually indicated in his passport), and also through the fault of the experimenter - when we, for example, “by eye” take readings from the needle of the same scales.
Among others, there are also so-called systematic measurement errors. It's already non-random errors that occur due to incorrect setup or operation of the device. For example, unregulated floor scales can steadily “add” kilograms, and the seller systematically weighs down customers. Or it can be calculated not systematically. However, in any case, such an error will not be random, and its expectation is different from zero.
…I’m urgently developing a sales training course =)
Let’s solve the inverse problem ourselves:
Example 5
The diameter of the roller is a random normally distributed random variable, its standard deviation is equal to mm. Find the length of the interval, symmetrical with respect to the mathematical expectation, into which the length of the roller diameter is likely to fall.
Point 5* design layout to help. Please note that the mathematical expectation is not known here, but this does not in the least prevent us from solving the problem.
And an exam task that I highly recommend to reinforce the material:
Example 6
A normally distributed random variable is specified by its parameters (mathematical expectation) and (standard deviation). Required:
a) write down the probability density and schematically depict its graph;
b) find the probability that it will take a value from the interval ![]() ;
;
c) find the probability that the absolute value will deviate from no more than ;
d) using the “three sigma” rule, find the values of the random variable.
Such problems are offered everywhere, and over the years of practice I have solved hundreds and hundreds of them. Be sure to practice drawing a drawing by hand and using paper tables;)
Well, I’ll look at an example of increased complexity:
Example 7
The probability distribution density of a random variable has the form ![]() . Find, mathematical expectation, variance, distribution function, build density graphs and distribution functions, find.
. Find, mathematical expectation, variance, distribution function, build density graphs and distribution functions, find.
Solution: First of all, let us note that the condition does not say anything about the nature of the random variable. The presence of an exponent in itself does not mean anything: it may turn out, for example, indicative or even arbitrary continuous distribution. And therefore the “normality” of the distribution still needs to be justified:
Since the function ![]() determined at any real value, and it can be reduced to the form
determined at any real value, and it can be reduced to the form  , then the random variable is distributed according to the normal law.
, then the random variable is distributed according to the normal law.
Here we go. For this select a complete square and organize three-story fraction:
Be sure to perform a check, returning the indicator to its original form:
, which is what we wanted to see.
Thus:  - By rule of operations with powers"pinch off" And here you can immediately write down the obvious numerical characteristics:
- By rule of operations with powers"pinch off" And here you can immediately write down the obvious numerical characteristics: ![]()
Now let's find the value of the parameter. Since the normal distribution multiplier has the form and , then:  , from where we express and substitute into our function:
, from where we express and substitute into our function:  , after which we will once again go through the recording with our eyes and make sure that the resulting function has the form
, after which we will once again go through the recording with our eyes and make sure that the resulting function has the form  .
.
Let's build a density graph: 
and distribution function graph  :
:
If you don’t have Excel or even a regular calculator at hand, then the last graph can easily be built manually! At the point the distribution function takes the value ![]() and here it is
and here it is
The normal distribution law is most often encountered in practice. The main feature that distinguishes it from other laws is that it is a limiting law, to which other laws of distribution approach under very common typical conditions (see Chapter 6).
Definition. A continuous random variable X hasnormal distribution law (Gauss's law)with parameters a and a 2, if its probability density has the form

The term “normal” is not entirely appropriate. Many signs obey the normal law, for example, the height of a person, the range of a projectile, etc. But if any characteristic obeys a distribution law different from normal, then this does not at all mean that the phenomenon associated with this characteristic is “abnormal.”
The normal distribution curve is called normal, or Gaussian, crooked. In Fig. 4.6, A, 6 the normal curve fd, (x) with parameters yio 2 are given, i.e. I[a] a 2), and the graph of the distribution function of the random variable X, which has a normal law. Let us pay attention to the fact that the normal curve is symmetrical with respect to the straight line x = a, has a maximum at the point X= A,
equal ![]() , i.e.
, i.e. 
And two inflection points x = a±
with ordinate 
It can be noted that in the normal law density expression, the parameters are indicated by the letters A and st 2, which we use to denote the mathematical expectation M(X) and variance OH). This coincidence is not accidental. Let us consider a theorem that establishes the probabilistic theoretical meaning of the parameters of the normal law.
Theorem. The mathematical expectation of a random variable X distributed according to a normal law is equal to the parameter a of this law, those.
A its dispersion - to the parameter a 2, i.e.
Expectation of a random variable X:

Let's change the variable by putting
Then ![]() the limits of integration do not change
the limits of integration do not change
and therefore

(the first integral is equal to zero as the integral of an odd function over an interval symmetric with respect to the origin, and the second integral  - Euler - Poisson integral).
- Euler - Poisson integral).
Variance of a random variable X:
Let's make the same change of variable x = a + o^2 t, as in the calculation of the previous integral. Then
Applying the method of integration by parts, we obtain
Let's find out how the normal curve will change when the parameters change A and with 2 (or a). If a = const, and the parameter changes a (a x a 3), i.e. the center of symmetry of the distribution, then the normal curve will shift along the abscissa axis without changing its shape (Fig. 4.7).


If a = const and the parameter a 2 (or a) changes, then the ordinate changes
curve maximum  As a increases, the ordinate of the maximum
As a increases, the ordinate of the maximum
the curve decreases, but since the area under any distribution curve must remain equal to one, the curve becomes flatter, stretching along the x-axis; when decreasing su, on the contrary, the normal curve extends upward while simultaneously compressing from the sides. In Fig. Figure 4.8 shows normal curves with parameters a 1 (o 2 and a 3, where o, A(aka mathematical expectation) characterizes the position of the center, and parameter a 2 (aka dispersion) characterizes the shape of the normal curve.
Normal distribution law of a random variable X with parameters A= 0, st 2 = 1, i.e. X ~ N( 0; 1), called standard or normalized and the corresponding normal curve is standard or normalized.
The difficulty of directly finding the distribution function of a random variable distributed according to the normal law according to formula (3.23) and the probability of its falling on a certain interval according to formula (3.22) is associated with the fact that the integral of the function (4.26) is “uncollectible” in elementary functions . Therefore they are expressed through the function
- function (probability integral) Laplace, for which the tables have been compiled. Let us recall that we have already encountered the Laplace function when considering the Moivre-Laplace integral theorem (see section 2.3). Its properties were also discussed there. Geometrically, the Laplace function Ф(.с) represents the area under the standard normal curve on the segment [-X; X] (Fig. 4.9) 1 .

Rice. 4.10

Rice. 4.9
Theorem. The distribution function of a random variable X, distributed according to the normal law, is expressed through the Laplace functionФ(х) according to the formula
According to formula (3.23), the distribution function is:

Let us make a change of variable, setting at X-> -oo? -» -00, therefore

1 Along with the probability integral of the form (4.29), representing the function Ф(х), its expressions are also used in the literature in the form of other tabulated functions:
representing the areas iodine of the standard normal curve, respectively, at the intervals (0; x], (-oo; x], [-x>/2; Chl/2 .
First integral

(due to the parity of the integrand and the fact that the Euler - Poisson integral is equal to [To).
The second integral, taking into account formula (4.29), is
Geometrically, the distribution function represents the area under the normal curve on the interval (-co, x) (Fig. 4.10). As we see, it consists of two parts: the first, on the interval (-oo, A), equal to 1/2, i.e. half of the entire area under the normal curve, and the second, on the interval (i, x),
equal to 
Let us consider the properties of a random variable distributed according to a normal law.
1. The probability of hitting a random variable X distributed according to a normal law is V interval[x 1(x 2 ], equal to
Considering that, according to property (3.20), the probability P(x,

where and Г 2 are determined by formula (4.33) (Fig. 4.11). ?
2. The probability that the deviation of a random variable X, distributed according to a normal law, from the mathematical expectation a will not exceed the value A > 0 ( in absolute value) is equal to
and also the oddity property of the Laplace function, we obtain

Where? =D/o (Fig. 4.12). ?
In Fig. 4.11 and 4.12 provide a geometric interpretation of the properties of the normal law.


Comment. Discussed in Chap. 2 the approximate integral formula of Moivre - Laplace (2.10) follows from the property (4.32) of a normally distributed random variable at x ( = a, x 2 = b ) a = pr
And ![]() So
So
as a binomial law of distribution of a random variable X = t with parameters P And R, for which this formula was obtained, with n -> OS tends to the normal law (see Chapter 6).
Similar are the consequences (2.13), (2.14) and (2.16) of the Moivre-Laplace integral formula for the number X = t occurrence of an event in P independent testing and its frequency t/n follow from properties (4.32) and (4.34) of the normal law.
Let us calculate the probabilities using formula (4.34) P(X-a e) at various values of D (we use Table II of the appendices). We get

This is where the “three sigma rule” comes from.
If a random variable X has a normal distribution law with parameters a and a 2, i.e. M(a; a 2), then it is almost certain that its values lie in the interval(a - For, A+ For).

Violation of the “three sigma rule”, i.e. deviation of a normally distributed random variable X more than 3 (but absolute value), is an almost impossible event, since its probability is very low:
Note that the deviation D in, at which  , called
, called
probable deviation. For the normal law D in « 0.675a, i.e. per interval (A - 0.675a, A+ 0.675a) accounts for half of the total area under the normal curve.
Let's find the skewness coefficient and kurtosis of a random variable X, distributed according to a normal law.
Obviously, due to the symmetry of the normal curve relative to the vertical line x = a, passing through the distribution center a = M(X), coefficient of asymmetry of the normal distribution A = 0.
Kurtosis of a normally distributed random variable X we find using formula (3.37), i.e. 
where we took into account that the central moment of the 4th order, found by formula (3.30) taking into account definition (4.26), i.e.

(we omit the calculation of the integral).
Thus, the kurtosis of a normal distribution is zero and the steepness of other distributions is determined in relation to the normal one (we already mentioned this in paragraph 3.7).
O Example 4.9. Assuming that the height of men of a certain age group is a normally distributed random variable X with parameters A= 173 and a 2 =36:
- 1) Find: a) the expression of the probability density and distribution function of the random variable X; b) the shares of suits of 4th height (176-182 cm) and 3rd height (170-176 cm), which must be provided in the total production volume for a given age group; c) quantile x 07 and the 10% point of the random variable X.
- 2) Formulate the “three sigma rule” for a random variable X. Solution. 1, a) Using formulas (4.26) and (4.30) we write

1, b) The share of suits of the 4th height (176-182 cm) in the total production volume will be determined by formula (4.32) as the probability


(Fig. 4.14), since according to formulas (4.33)

The share of suits of the 3rd height (170-176 cm) could be determined similarly to formula (4.32), but it is easier to do this using formula (4.34), given that this interval is symmetrical with respect to the mathematical expectation A = M(X) = 173, i.e. inequality 170 X X -173|
(see Fig. 4.14;.
1, c) Quantile x 07(see paragraph 3.7) random variable X we find from equation (3.29) taking into account formula (4.30):

where 
According to the table We find 11 applications I- 0.524 and
This means that 70% of men in this age group are up to 176 cm tall.
- The 10% point is the ego quantile x 09 = 181 cm (located similarly), i.e. 10% of men are at least 181 cm tall.
- 2) It is almost certain that the height of men in this age group lies within the boundaries of A- Z = 173 - 3 6 = 155 to a + Zet = 173 + 3 - 6 = = 191 (cm), i.e. 155
Due to the features of the normal distribution law noted at the beginning of the section (and in Chapter 6), it occupies a central place in the theory and practice of probabilistic statistical methods. The great theoretical significance of the normal law is that with its help a number of important distributions are obtained, which are discussed below.
- Arrows in Fig. 4.11-4.13 the conventional areas and corresponding figures under the normal curve are marked.
- The values of the Laplace function Ф(х) are determined from the table. II applications.